Building a High-Throughput FIX Server
From Single-Core Efficiency to Multi-Core Scaling
Introduction
In this article, we explore what it takes to reach 600K+ FIX messages per second throughput in a FIX server. This throughput was measured on a 16-core server, and the same design can scale beyond one million messages per second on hosts with more CPU cores.
For a quick introduction to the FIX protocol, see my earlier article:
https://akinocal1.substack.com/i/193450018/basics-of-fix-and-what-we-are-measuring
For a FIX server, this starts with an optimised receive path that performs well on a single CPU core. Once the single-core path is efficient, the next step is scaling across multiple cores while minimising contention.
The following sections first present the benchmark results, then explain the implementation techniques used to achieve them.
The benchmarks and techniques presented in this article are based on llfix, a low-latency C++ FIX engine, available as both an open-source edition (https://github.com/CorewareLtd/llfix) and a commercial edition (www.llfix.net).
Benchmarks
The benchmark server details are as below :
Hwloc/lstopo output of the benchmark server is as below :
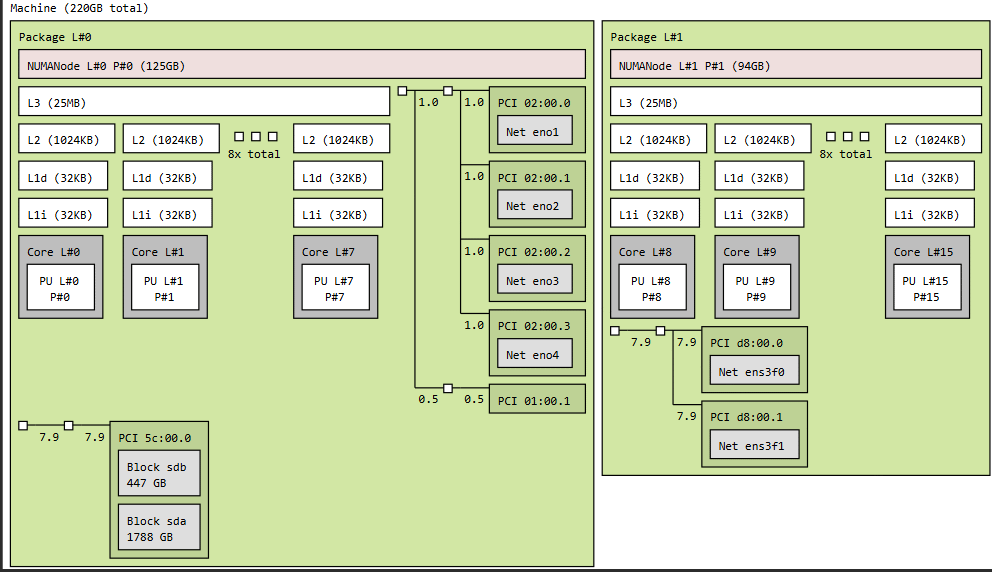
As for tunings, CPU frequency was maximised and hyperthreading was disabled.
In this benchmark, the FIX server and FIX client applications run on the same host and communicate over the loopback device. This setup is used to minimise the effect of external networking and packet losses so the benchmark focuses mainly on the server-side FIX receive path.
The client application starts multiple FIX clients, all connected to the FIX server application running the FIX acceptor. Each FIX client sends 150,000 messages. Also at the same time, the FIX server sends execution reports back to all connected FIX clients.
Throughput is measured using RDTSCP timestamps recorded by the FIX server during memory-mapped-file-based message serialisation. The Python script used to calculate throughput is available here:
The measured path includes:
Receiving and parsing the incoming FIX message
Session-level validations, including fundamental FIX session checks
FIX dictionary validations, used dictionaries:
- https://github.com/CorewareLtd/llfix/blob/main/tests/dictionaries/FIX50SP2.xml
- https://github.com/CorewareLtd/llfix/blob/main/tests/dictionaries/FIXT11.xml
Stale timestamp validation
Message serialisation to the file system
The message sent from clients to the server is as below :
Message :
8=FIXT.1.1|9=188|35=D|34=2|
49=CLIENT1|52=20251231-17:42:03.736004873|
56=EXECUTOR|11=1|55=BMWG.DE|
54=1|38=1|44=5|40=2|59=0|
453=2|
448=PARTY1|447=D|452=1|
448=PARTY2|447=D|452=3|
60=20251231-17:42:03.736004873|
10=077|
Results:
RX Latency
This section focuses on receive-side latency because the cost of receiving, parsing, validating, and dispatching incoming FIX messages directly affects overall server throughput.
Reactor IO pattern: llfix uses a reactor-style design based on readiness-based I/O multiplexing. On Linux, this is implemented with epoll.
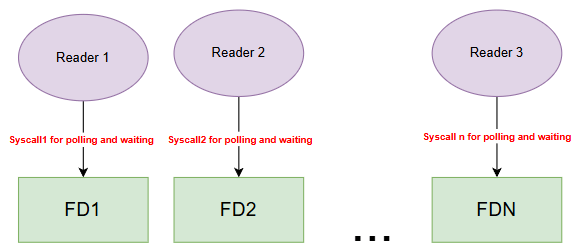
Instead of dedicating a blocking synchronous receive path to each socket, the server can monitor multiple sockets and process the ones that are ready for reading. For a FIX acceptor handling many client sessions, this avoids unnecessary blocking and scales better than a simple synchronous socket-per-wait model.
The diagram below illustrates the case without epoll :
As for the case with epoll :
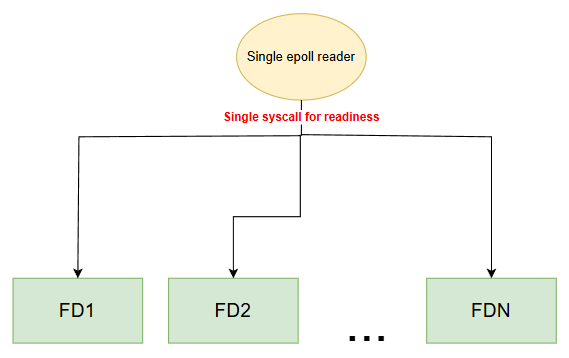
Why epoll ? : epoll was chosen for its maturity, broad kernel support, and predictable behaviour across production Linux environments. io_uring is a promising interface, but its availability varies across kernel versions and some environments restrict it.
That said, the TCP reactor in llfix is template-based, making an io_uring-backed reactor a natural future experiment.
No data copies: llfix uses llfix::FixStringView, which is conceptually similar to std::string_view: it stores a pointer and a length.
Source : https://github.com/CorewareLtd/llfix/blob/main/include/llfix/fix_string_view.h
During RX processing, these views point directly into the network I/O buffers. This allows llfix to reference incoming FIX field values without copying them into separate strings.
No memory allocations: llfix uses a single incoming message instance per session.
That message instance uses a memory pool to store llfix::FixStringView objects representing incoming FIX field values. This avoids dynamic memory allocation during normal RX message processing.
Avoiding allocations on the hot path helps both latency and determinism, since allocator calls can introduce unpredictable tail latency.
Message type compression: A FIX engine needs to perform per-message-type processing during RX. Examples include validating incoming message types and handling repeating groups, which are defined per message type.
In FIX, message types are carried in tag 35, and they can contain multiple ASCII characters. One optimisation used in llfix is packing FIX message types into 32-bit integers. This allows message type checks and lookups to work on compact integer values instead of repeatedly comparing and hashing character sequences. The implementation “llfix::pack_message_type” can be seen at https://github.com/CorewareLtd/llfix/blob/main/include/llfix/fix_utilities.h
This optimisation also introduces a deliberate limitation: llfix supports message types up to 4 characters long.
SIMD for checksum validations: SIMD (Single Instruction Multiple Data) allows one CPU instruction to operate on multiple data elements in parallel. In llfix RX path, AVX2 SIMD intrinsics are used for FIX checksum validation.
Below is a benchmark comparison between 1 million iterations of checksum validation with and without SIMD (AVX2):
The SIMD-enabled utility methods can be found here:
https://github.com/CorewareLtd/llfix/blob/main/include/llfix/fix_utilities.h
Decoder benchmark: The llfix decoder benchmark measures only FIX decoding, without networking and without concurrency. This makes it useful as a baseline for understanding the receive-side parsing and validation cost before adding networking and multi-session effects.
The message used : 8=FIX.4.2|9=161|35=8|34=1|49=EXECUTOR|52=20230901-12:30:45.000|56=TRADER|17=12345|20=0|37=ABC123|39=1|11=1|150=1|32=1|31=100|453=2|448=PARTY1|447=D|452=1|448=PARTY2|447=D|452=3|10=255|
Its source and introductions for reproduce : https://github.com/CorewareLtd/llfix/tree/main/benchmarks/decoder
Concurrency implementation
CPU frequencies have largely stopped increasing at the historical rate, mainly because of power and thermal constraints. Instead, CPU vendors such as Intel and AMD have focused on adding more cores. As a result, for server-side applications, an important performance strategy is often vertical scaling: using the available cores on a multicore server as efficiently as possible.
llfix approach is utilising 1 thread and CPU core for acceptor thread for accepting TCP connection and also processing FIX logons and utilising all other cores for processing FIX sessions :
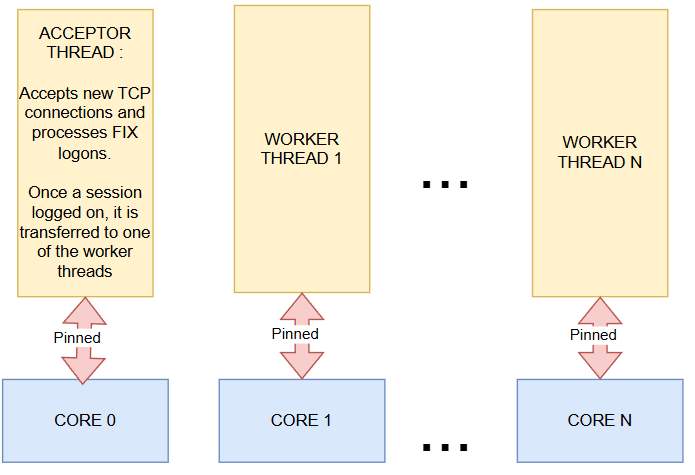
The acceptor thread must identify which FIX session a TCP connection belongs to and validate the logon process before handing the session off to a worker thread. Performing this step on a worker thread would introduce a race condition around FIX session ownership. For that reason, a session is dispatched to a worker thread only after a successful FIX logon.
After a successful logon, the session is assigned to one of the worker threads. From that point on, each session is processed only by its assigned worker thread. New incoming FIX sessions are distributed across worker threads in a round-robin fashion. Each worker thread owns its own epoll instance, allowing it to monitor and process the sockets assigned to that worker independently.
For configurability, llfix checks the worker_thread_count parameter, which is 0 by default. In the default configuration, llfix detects the number of physical CPU cores on the host and creates the same number of worker threads, with each thread pinned to a dedicated core. If worker_thread_count is explicitly specified, llfix uses that value instead. In both cases, the acceptor and worker threads are automatically pinned to the corresponding host CPU cores.
Minimised lock contention and cache-coherency traffic
To avoid race conditions, each FIX session uses its own pool of llfix::FixStringView objects. This removes the need to share those resources across sessions and eliminates a potential source of contention.
llfix::FixServer also has a small number of shared resources used to track connectors. These resources may be accessed by FIX sessions running on different worker threads during connection and disconnection handling. To protect this area, llfix uses a TTAS-based userspace spinlock.
TTAS stands for “test and test-and-set”:
https://en.wikipedia.org/wiki/Test_and_test-and-set
The reason this matters is cache coherency. A spinlock is usually represented by a small flag in memory, but that flag still lives inside a CPU cache line. When multiple cores repeatedly try to modify the same lock variable, the cache line containing that flag keeps moving between cores in an exclusive or modified state. That generates cache-coherency traffic and increases contention.
Cache coherency protocols are needed to avoid data hazards. Intel CPUs use MESIF and AMD CPUs use MOESI, however both heavily depend on MESI protocol. There are 4 states for a CPU cache line in MESI protocol, which are M for modified , E for exclusive , S for shared and I for invalid. The diagrams below are illustrating the simplest cases for all 4 states :
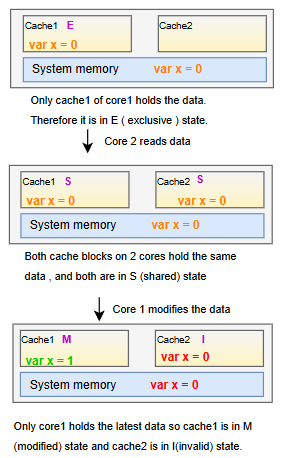
(The diagram is taken from the Microarchitecture cheatsheet https://github.com/akhin/microarchitecture-cheatsheet )
Instead of repeatedly attempting to acquire the lock, as in TAS (test-and-set), TTAS repeatedly checks whether the lock appears to have been released. This approach helps reduce cache-coherency protocol traffic.
As for a benchmark, you can find tas_lock.cpp on https://gist.github.com/akhin/aa184d189502dd74225ea22ada3601a2 and ttas_lock.cpp on https://gist.github.com/akhin/7d646e772255ffbc7dd4b1c6f9cde9c2 . Both create 8 threads where each thread locks and unlocks 1 million times. You can see perf based cache miss stats as below:
[root@localhost locks]# sudo perf stat -e L1-dcache-load-misses,L1-dcache-loads ./tas_lock
Performance counter stats for ‘./tas_lock’:
25,590,649 L1-dcache-load-misses # 35.53% of all L1-dcache accesses
72,023,440 L1-dcache-loads
1.543512059 seconds time elapsed
[root@localhost locks]# sudo perf stat -e L1-dcache-load-misses,L1-dcache-loads ./ttas_lock
Performance counter stats for ‘./ttas_lock’:
20,356,094 L1-dcache-load-misses # 20.07% of all L1-dcache accesses
101,448,847 L1-dcache-loads
1.279792148 seconds time elapsed
Finally, llfix provides a management server that supports administrative commands such as querying and updating sequence numbers. Synchronisation is not required for read-only commands such as get_incoming_sequence_number. However, it is required for mutating commands such as set_incoming_sequence_number, because the management server’s reactor runs on its own thread.
For this purpose, llfix uses a fixed-size SPSC lock-free queue:
https://github.com/CorewareLtd/llfix/blob/main/include/llfix/core/utilities/spsc_bounded_queue.h
Conclusion
Reaching 600K+ FIX messages per second in a FIX server is not the result of a single optimisation. It comes from removing avoidable work from the hot path, then scaling that efficient path across CPU cores with minimal contention.
On the receive side, llfix focuses on keeping message processing predictable: using asynchronous I/O, avoiding unnecessary data copies, avoiding dynamic memory allocations, using compact message-type representations, and applying SIMD where it makes sense. These optimisations reduce the per-message cost before concurrency is even introduced.
From there, vertical scalability depends on ownership and isolation. In llfix, each FIX session is processed by one assigned worker thread after a successful logon. This keeps session state local to one thread, reduces synchronisation requirements, and makes CPU-core scaling more practical. Shared resources are kept minimal, and where synchronisation is required, it is kept away from the main RX path as much as possible, mainly around connection and disconnection handling.
The benchmark results show the scaling behaviour clearly. In the single-threaded configuration, throughput stayed roughly flat at around 233K messages per second as the number of clients increased from 2 to 8, showing that the single processing thread was the limiting factor. In the multithreaded configuration, throughput increased as more client sessions were added, reaching 617,032 messages per second with 8 clients on a 16-core host, with message serialisation and validations included. The same design can scale further on hosts with more physical CPU cores.